RavenDB’s Index Store, Indexing Process and Eventual Consistency
In RavenDB, indexes play a crucial part in answering queries. Without them, it is impossible to find data on anything other than the document ID, and therefore RavenDB becomes just a bloated key/value store. Indexes are the piece of the puzzle that allows rich queries for data to be satisfied efficiently. In this article, based on chapter 3 of RavenDB in Action, we will explain how indexes work in RavenDB.
RavenDB has a dedicated storage for documents called the Document Store. The Document Store has one important feature - it is very efficient at pulling documents out by their ID. However, this is also its only feature, and the only way it can find documents. It can only have one key for a document, and that key is always the document ID; documents cannot be retrieved based on any other criteria.
When you need to pull documents out of the Document Store based on some search criteria other than their ID, the Document Store itself becomes useless. To be able to retrieve documents using some other properties they have, you need to have indexes. Those indexes are stored separately from the documents in what we call the Index Store.
In this article, you will learn about indexes and the indexing process in RavenDB.
The RavenDB indexing process
Let’s assume for one moment all we have in our database is the Document Store with a couple of million documents, and now we have a user query we need to answer. The document store by itself can’t really help us, as the query doesn’t have the document IDs in it. What do we do now?
One option is to go through all the documents in the system and check them one by one to see if they match the query. This is going to work, sure, if the user who issued the query is kind enough to wait for a few hours in a large system. But no user is. In order to efficiently satisfy user queries, we need to have our data indexed. By using indexes, the software can perform searches much more efficiently and complete queries much faster.
Before we look at those indexes, let’s consider for a moment when they are going to be built or updated with the new documents that come in. If we calculate them when the user issues the query, we again delay returning the results. This is going to be much less substantial than going over all the documents, but that still is a performance hit we incur to the user for every query he makes.
Another, perhaps more sensible option is to update the indexes when the user puts the new documents. This indeed makes more sense at first, but then when you start to consider what it would take to update several complex indexes on every put, it becomes much less attractive. In real systems, this means writes would take quite a lot of time, as now not only the document is being written, but all indexes have to be updated as well. There is also the question of transactions: what happens when a failure occurs while the indexes are being updated?
With RavenDB, a conscious design decision was made to not cause any wait due to indexing. There should be no wait at all, never when you ask for data, and also never during other operations—like with adding new documents to the store.
So when are indexes updated?
RavenDB has a background process that is handed new documents and document updates as they come in, right after they were stored in the document store, and it passes them in batches through all the indexes in the system. For write operations, the user gets an immediate confirmation of their transaction even before the indexing process started processing these updates—without waiting for indexing but certain the changes were recorded in the database. Queries do not wait for indexing; they just use the indexes that exist at the time the query is issued. This ensures both smooth operation on all fronts and that no documents are left behind. You can see this in figure 1.
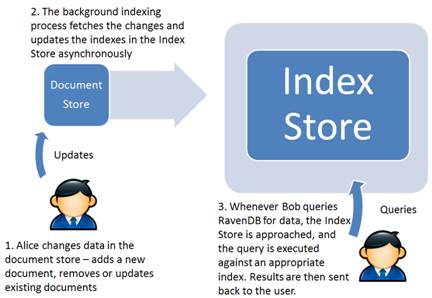
It all sounds suspiciously good, doesn’t it? Obviously, there is a catch. Since indexing is done in the background when enough data comes in, that process can take a while to complete. This means it may take a while for new documents until they appear in query results. While RavenDB is highly optimized to minimize such cases, it can still happen. When this happens, we say the index results are stale. This is by design, and we discuss the implications of that in the end of this article.
What is an Index?
Consider the following list of books:
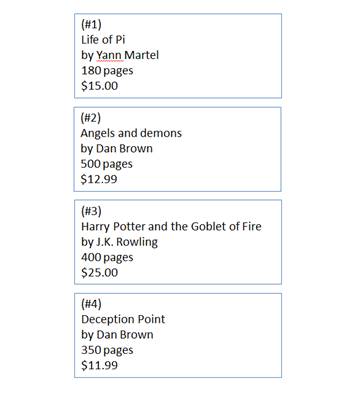
If I asked you about the price of the book written by J.K. Rowling, or to name all the books with more than 600 pages in them, how would you find the answer to that? Obviously going through the entire list is not too cumbersome when there are only 10 books in it, but it becomes a problem rather quickly as the list grows.
An index is just a way to help us answer such questions more quickly. It is all about making a list of all possible values grouped by their context and ordering it alphabetically. As a result, the list of books becomes the following lists of values, each value accompanied by the book number it was taken from.
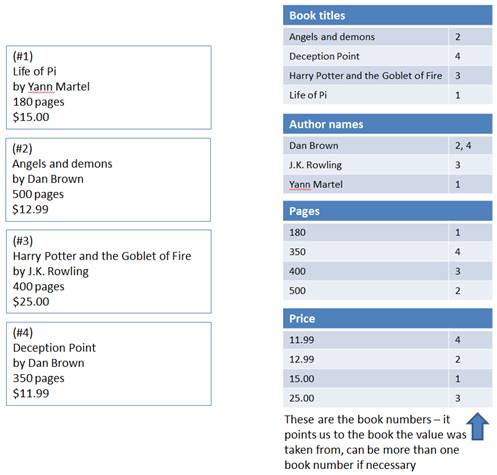
Since the values are grouped by context (the title, author name, and so on) and are sorted alphabetically, it is now easy to find a book by any of those values even if we had millions of them. You simply go to the appropriate list (say, author names) and look up the value. Once the value has been found in the list, the book number that is associated with it is returned and can be used to get the actual book if you need more information on it.
RavenDB uses Lucene.NET as its indexing mechanism. Lucene.NET is the .NET port of the popular open—source search engine library Lucene. Originally written in Java and first released in 2000, Lucene is the leading open-source search engine library. It is being used by big names like Twitter, LinkedIn, and others to make their content searchable and is constantly being improved.
A Lucene index
Since RavenDB indexes are in fact Lucene indexes, before we go any deeper into RavenDB indexes, we need to familiarize ourselves with some Lucene concepts. This will help us understand how things work under the hood and allow us to work better with RavenDB indexes.
In Lucene, the base entity that is being indexed is called a document. Every search yields a list of matching documents. In our example, we search for books, so each book would be a Lucene document. Just like books have title, author name, page count, and so on, oftentimes we need to be able to search for documents with more than one piece of data taken from each. For this end every document in Lucene has the notion of fields, which are just a logical separation between different parts of the document we indexed. Each field in a Lucene document can contain different pieces of information about the document that we can later use to search on.
Applying these concepts to our example, in Lucene, each book would be a document, and each book document would have the title, author name, price, and pages count fields. Lucene creates an index with several lists of values, one for each field, just as shown in figure 3. To complete the picture, each value that is put in the index in one of those lists (for example, “Dan Brown” from 2 books into the author names field) is called a term.
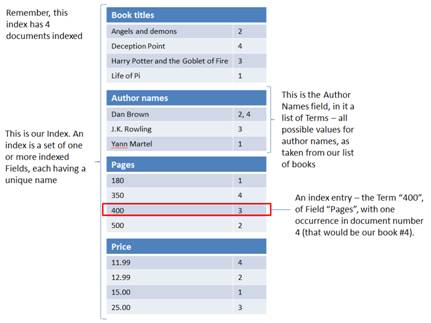
Searches are made with terms and field names to find matching documents, where a document is considered a match if it has the specified terms in the searched fields, as in the following pseudo-query: all book documents with the author field having a value of “Dan Brown.” Lucene allows for querying with multiple clauses on the same field or even on different fields, so queries like “all books with author Dan Brown or J.K. Rowling, and with price lower than 50 bucks” are fully supported.
An index in RavenDB is just a standard Lucene index. Every RavenDB document from the document store can be indexed by creating a Lucene document from it. A field in that Lucene document is then going to be a searchable part of the RavenDB document we are indexing. For example, the title of a blog post, the actual content, and the posting date, each will be a field.
Queries are made against one index, on one field or more, using one term or more per field. Next up, you’ll see how exactly that falls into place.
The process in which Lucene documents are created from documents stored in RavenDB - from raw structured JSON to a flat structure of documents and fields - is referred to as map/reduce. This is a two-stage process where first the actual data is projected out of the document (aka being Mapped), and then optionally gets processed or transformed into something else (aka being Reduced). Starting in the next section we will go through RavenDB’s map/reduce process and work our way to properly grokking it.
Eventual consistency
Before we go and have a look at actual indexes, allow me to pause for a minute or two to discuss the implications of indexing asynchronously. As we explained in the beginning of the chapter indexing in RavenDB happens in the background, so on a busy system new data may take a while to appear in query results. Databases behaving this way are said to be eventually consistent, meaning that at some point in time new data is guaranteed to appear in queries but it isn’t guaranteed to happen immediately.
At first glance, getting stale results for queries doesn’t seem all too attractive. Why would I want to work with a database that doesn’t always answer queries correctly?
This is mostly because we are used to databases that are implemented with the (atomicity, consistency, isolation, and durability) ACID properties in mind. In particular, relational databases are ACID and always guarantee consistent results. To our context what that means is every query you send will always return with the most up-to-date results, or, in other words, they are immediately consistent. If a document exists in the database when the query is issued, you are guaranteed it will be returned in all matching queries.
But is that really required? Document store is immediately consistent, queries are eventually consistent: with RavenDB, eventual consistency is only the case when querying. Loading a document by ID is always Immediately Consistent, and fully ACID compatible.
Even when results are known to be 100 percent accurate and never stale like they are in any SQL database, during the time it takes the data to get from the server to the user’s screen plus the time it takes the user to read and process the data and then to act on it, the data could have changed on the server without the user’s knowledge. When there is high network latency or caching involved, that’s is even more likely. And, what if the user went to get coffee after asking for that page of data?
In the real world, when it comes down to business, most query results are stale or should be thought of as such.
Although the first instinct is to resist the idea, when it actually happens to us we don’t fight it and usually even ignore it. Take Amazon for example: having an item in your cart doesn’t ensure you can buy it. It can still run out of stock by the time you check out. It can even run out of stock after you check out and pay, in which case Amazon’s customer relations department will be happy to refund your purchase and even give you a free gift card for the inconvenience. Does that mean Amazon is irresponsible? No. Does that mean you were cheated? Definitely not. It is just about the only way they could efficiently track stock in such a huge system, and we as users almost never feel this happen.
Now, think about your own system and how up to date your data should really be on display. Could you accept query results showing data that is 100 percent accurate as of a few milliseconds ago? Probably so. What about half a second? One second? Five seconds? One minute?
If consistency is really important, you wouldn’t accept even the smallest gap, and if you can accept some staleness, you could probably live with also some more. The more you think of it, the more you come to realize it makes sense to embrace it rather than fight it.
At the end of the day, no business will refuse a transaction even if it was made by email or fax and the stock data have changed. Every customer counts, and the worst that could happen is an apology. And that is what stale query results are all about.
As a matter of fact, a lot of work has been put making sure the periods in which indexes are stale are as minimal as possible. Thanks to many optimizations, most stale indexes you will see are new indexes that were created in a live system with a lot of data in it or when there are many indexes and a lot of new data keeps coming in consistently. In most installations, indexes will be non-stale most of the time, and you can safely ignore the fact they are still catching up when they are indeed stale. For when it is absolutely necessary to account for stale results, RavenDB provides a way to know when the results are stale and also to wait until a query returns non-stale results.
Summary
Having a scalable key/value store database is nice, but indexes are what really make RavenDB so special. Indexes make querying possible and efficient, and the more flexible indexes are, the more querying possibilities you have.
In this article, we laid the basics for understanding indexes in RavenDB and became familiar with RavenDB’s novel approach to indexing. We talked about the asynchronous indexing process and possibility of getting stale results, although in most real-world cases you will hardly even notice that.